
ℹ️ Hinweis ← (hier klicken)
Aufgabe 11
Bei dieser Aufgabe müssen ein paar Informationen aus dem Text und der dargestellten Tabelle abgelesen werden.
In der Tabelle sind die Ergebnisse für fünf verschiedene t-Test für unabhängige Stichproben dargestellt. Es wurden jeweils die Mittelwerte der beiden Gruppen "OER" und "Trad" verglichen.
Lösungen:
- 💡 A ist falsch: Im letzten Absatz über der Tabelle steht, dass der Unterschied der Gesamtpunktzahlen ("total exam points") nicht signifikant ist. p=0.188
- 💡 B ist falsch: Die Anzahl der Teilnehmer ist das jeweilige Groß N in der Tabelle. Das ist praktisch für jeden Test anders.
- 💡 C ist richtig: Bei jedem der 5 Tests ist der Mittelwerte der Gruppe "Trad" größer.
- 💡 D ist richtig
- 💡 E ist falsch: Aus dem Text ergibt sich nicht, dass eine bestimmte Richtung vermutet wurde. Das Vorzeichen des t-Wertes hängt einfach nur davon ab, wie der t-Test die Differenz berechnet hat, also entweder OER minus Trad oder Trad minus OER. Hier wurde offensichtlich ℹ️ OER minus Trad gerechnet.
Aufgabe 12
Auch bei dieser Aufgabe geht es darum, einige Informationen (aus dem englischen Text) abzulesen.
Die Schwierigkeit bei dieser Aufgabe hat im Grunde nichts mit Statistik zu tun. Eigentlich geht es nur darum, den englischen Text richtig ins Deutsche zu übersetzen.
Lösungen:
- 💡 A ist falsch: Im Text steht: "a two-tailed power calculation". Es geht also um einen zweiseitigen Test.
- 💡 B ist falsch: Im Text steht: "that a sample size of 68 has a 80.0% power". Sie möchten also eine Power von 80%.
- 💡 C ist falsch: Sie verwenden insgesamt 74 Proband:innen. Aber eigentlich brauchen sie nur 68, also 34 pro Gruppe "(34 per group)".
- 💡 D ist falsch: Sie orientieren sich an den Effektgrößen, die in einem recent meta-analytic review berichtet wurden. Von irgendwelchen Richtwerten ist keine Rede.
- 💡 E ist richtig: "…shows that a sample size of 68 has a 80% power to detect at p<0.05 an effect size of d=0.7…"
Aufgabe 13
Diese Aufgabe ist ähnlich wie Aufgabe 14 aus der Klausur 03/2021.
Lösungen:
- 💡 A ist falsch: ℹ️ Factor with 4 levels heißt, dass es vier Ausprägungen gibt.
- 💡 B ist falsch: Richtig wäre
augen$alter(wie indatensatz$variable). - 💡 C ist falsch: R unterscheidet zwischen Groß- und Kleinschreibung. Eine
MEAN()-Funktion gibt es nicht. - 💡 D ist richtig: ℹ️ Zuerst kommt die Zeile, dann die Spalte.
- 💡 E ist richtig: Das "wide format" ist das ganz normale Anzeigeformat für einen Data Frame.
Aufgabe 14
Diese Aufgabe ist ähnlich wie die Aufgabe 4 aus der Klausur 09/2021 und die Aufgabe 5 aus der Klausur 03/2021.
Beim dargestellten Diagramm handelt es sich im Grunde um zwei Streudiagramme, die in einem Bild dargestellt werden.
Das nennt man auch gruppiertes Streudiagramm: Für jede Gruppe ein Streudiagramm.
Beispiel um die Aufgabe zu veranschaulichen:
Was nun folgt, ist die Rekonstruktion des Streudiagramms aus der Aufgabe.
Zuerst erfassen wir die erreichten Punktezahlen der Expertengruppe:
punkte_exprt <- c(80, 90, 100, 60, 70, 80, 70, 100, 40, 80, 90, 100, 80, 90, 100, 60, 90, 60, 70, 80, 60, 80, 100, 70, 90, 100, 50, 60, 100)
Dann die Punktezahlen für die Kontrollgruppe:
punkte_kontr <- c(30, 20, 50, 50, 60, 50, 30, 40, 50, 60, 50, 60, 70, 10, 60, 70, 80, 60, 80, 90, 100, 50, 70, 90, 10, 70)
Und jetzt führen wir alle Punktezahlen in einem gemeinsamen Vektor zusammen, damit wir daraus dann am Ende einen Date Frame für alle Daten machen können:
punkte <- c(punkte_exprt, punkte_kontr)
Dasselbe machen wir jetzt für die Werte für das jeweilige Interesse am Thema:
interesse_exprt <- c(1, 1, 1, 2, 2, 2, 3, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 7, 7, 8, 8, 8, 9, 9, 9, 10, 10, 10)
interesse_kontr <- c(1, 2, 2, 3, 3, 4, 5, 5, 5, 5, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8, 9, 9, 9, 10, 10)
interesse <- c(interesse_exprt, interesse_kontr)
Jetzt basteln wir uns noch ein Gruppierungsvariable dazu und zeigen alles zusammen als Data Frame an:
gruppe <- c( rep(1,29), rep(2,26) )
(es gibt 29 Experten und 26 Mitglieder der Kontrollgruppe)
gruppe <- factor(gruppe, levels=c(1,2), labels=c("Experten", "Kontrolle"))
daten <- data.frame(gruppe, interesse, punkte)
daten
gruppe interesse punkte
1 Experten 1 80
2 Experten 1 90
3 Experten 1 100
4 Experten 2 60
5 Experten 2 70
...
30 Kontrolle 1 30
31 Kontrolle 2 20
32 Kontrolle 2 50
33 Kontrolle 3 50
34 Kontrolle 3 60
35 Kontrolle 4 50
...
Für diesen Data Frame können wir jetzt ein gruppiertes Streudiagramm für die beiden Gruppen Experten und Kontrolle anzeigen.
Zuerst definieren wir noch zwei verschiedene Arten von Punkten (shapes, colors und linewd für die Formen, Farben und Linien):
shapes <- c(3, 19)[as.numeric(daten$gruppe)]
colors <- c("blue", "red")[as.numeric(daten$gruppe)]
linewd <- c(3, 1)[as.numeric(daten$gruppe)]
Und dann kommt das eigentliche Streudiagramm:
plot(daten$punkte ~ daten$interesse, pch=shapes, col=colors, lwd=linewd, xlim=c(0,10), ylim=c(0,120))
Zum Schluss kommen noch die beiden Regressionsgeraden und die Legende dazu:
abline(lm(punkte_exprt ~ interesse_exprt), col="blue")
abline(lm(punkte_kontr ~ interesse_kontr ), col="red")
legend("topright", c("Experten","Kontrolle"), pch=c(3, 19), col=c("blue", "red"))
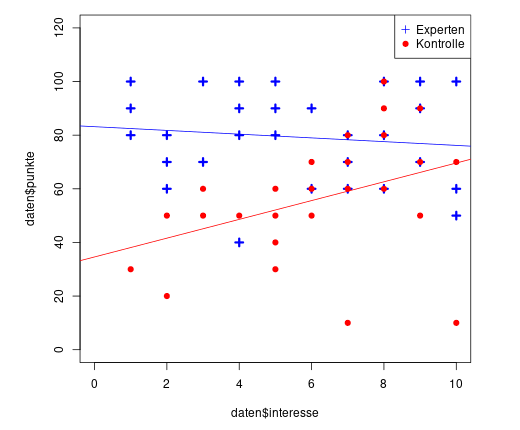
Lösungen:
- 💡 A ist richtig: "Der y-Achsenabschnitt" ist der Schnittpunkt der Regressionsgerade mit der y-Achse. In der Expertengruppe ist der bei ungefähr 80 und in der Kontrollgruppe bei ungefähr 35.
- 💡 B ist falsch: Bei der Expertengruppe gibt es eine fallende Gerade. Der Zusammenhang ist hier also negativ: Je größer das Interesse, desto schlechter das Abschneiden im Test. Nur die Kontrollgruppe hat eine steigende Gerade.
- 💡 C ist richtig
- 💡 D ist falsch: Theoretisch ist das richtig. Aber man kann in der Grafik ja nicht erkennen, ob es vielleicht mehrere Punkte auf demselben Fleck gibt, die sich gegenseitig überdecken. Also entspricht die Anzahl der Punkte nicht in jedem Fall der Stichprobengröße.
- 💡 E ist richtig: In der Kontrollgruppe gehen die Punkte von 10 bis 100 (die Spannweite ist also 90) und die Kreuze der Expertengruppe gehen von 40 bis 100 (die Spannweite ist also 60).
Aufgabe 15
Lösungen:
- 💡 A ist richtig: Im Sedlmeier, S.313/314, Abschnitt "Was ist Wahrscheinlichkeit", wird ℹ️ der klassische Ansatz den ℹ️ frequentistischen WSKen sozusagen gegenübergestellt. Siehe auch Aufgabe 5A aus der Klausur 09/2021.
- 💡 B ist richtig: Um dir diese ganzen Zusammenhänge nochmal grundlegend zu vergegenwärtigen, siehe vielleicht nochmal das Video zur empirischen Unabhängigkeit, und auch das Video zur stochastischen Unabhängigkeit. Siehe auch Sedlmeier S.317.
- 💡 C ist richtig: "Bernoulli-Experiment" ist ein hochtrabendes Wort für z.B. einen Münzwurf. Das Bernoulli-Experiment liegt praktisch jeder Binomialverteilung zugrunde. Wie z.B. beim Werfen einer Münze. Zur Binomialverteilung siehe z.B. die entsprechende Zusammenfassung in Lektion 4. Siehe auch Sedlmeier S.323.
- 💡 D ist richtig: Die Inferenzstatistik ist die schließende Statistik. Es geht immer darum, von einer Stichprobe auf die Population zu schließen. Siehe die Inferenzstatistik Grundlagen in Lektion 6.
- 💡 E ist richtig: Das kann man sich leicht mit einem ℹ️ kleinen Schaubild klarmachen. Siehe auch Aufgabe 5D aus der Klausur 09/2021.
Aufgabe 16
Lösungen:
- 💡 A ist richtig: Siehe Cohen’s d vs. Hegdes’ g. Siehe auch Sedlmeier S.292/293.
- 💡 B ist richtig: Eigentlich müsste es heißen: Das Cohens d für einen Mittelwertunterschied von zwei Gruppen lässt sich in den Korrelationskoeffizienten r umrechnen. Das ist hier gemeint. Dennoch: im ersten Augenblick leuchtet es überhaupt nicht ein, wie man ein Abstandsmaß wie Cohens d in den Korrelationskoeffizienten r umrechnen könnte. ℹ️ Welchen Sinn soll das ergeben? Und ℹ️ warum ist das überhaupt wichtig? Siehe auch Aufgabe 10D aus der Klausur 09/2021 und Aufgabe 11E aus der Klausur 03/2021.
- 💡 C ist richtig: Ein t-Wert (und ein p-Wert) ist immer auch von der Stichprobengröße abhängig. Aber die Effektgrößen kann man unabhängig von der Stichprobengröße direkt miteinander vergleichen.
- 💡 D ist falsch: Hier ist vielleicht nicht gleich auf Anhieb klar, was überhaupt die Frage ist. Die eigentliche Frage bei dieser Aussage ist, ob man Effektgrößen auch aus anderen Kennzahlen berechnen kann, also dann, wenn die Rohdaten gar nicht vorliegen und man nur bestimmte Kennzahlen weiß (siehe dazu vielleicht auch die Aufgabe 11B aus der Klausur 03/2021, dort ist eine ähnliche Aufgaben wesentlich konkreter formuliert).
Nehmen wir nun als Beispiel einfach mal die Effektgröße Cohens d. So ist etwa das Cohens d für einen Mittelwertunterschied nichts weiter als die Differenz der beiden Mittelwerte gemessen in Standardabweichungen:

Es ist also völlig normal, dass man Cohens d nicht direkt aus den Rohdaten berechnet, sondern aus anderen Kennwerten (welche ihrerseits zuvor vielleicht aus Rohdaten berechnet wurden). Hier sind das die beiden Mittelwerte, sowie die gepoolte Standardabweichung.
Zwei weitere Anmerkungen dazu:
Um diese Inhalte zu nutzen, musst du dich anmelden und den Zugriff auf die Klausurlösungen kostenpflichtig erwerben. - 💡 E ist richtig: η2 (Eta Quadrat) ist eine Effektgröße für die Varianzanalyse. Siehe Sedlmeier S.456.
Aufgabe 17
Diese Aufgabe ist ähnlich wie Aufgabe 12 aus der Klausur 09/2021.
Lösungen:
- 💡 A ist falsch: Offenbar hat der Lehrstuhl diese Aussage als falsch bewertet. Das würde ich anders sehen. Der Forschungsartikel wurde in diesem Fall zwar abgelehnt. Aber das ändert nichts daran, dass all die beschriebenen Bemühungen überhaupt nur unternommen wurden, weil es einen Publikationsbias gibt. So lauten auch die Ausführungen im ↗️ Feedbackbrief, die ich in diesem Fall unterstützen würde. Der Publikationsbias ist keine spezielle Praxis, sondern er ist praktisch das Ausgangsproblem für all die anderen Praktiken, die im Sedlmeier ab Seite 632 beschrieben werden. So wie die Frage formuliert ist ("Probleme in der Forschungspraxis"), müsste man diese Aussage eigentlich als richtig werten.
- 💡 B ist richtig: Eine entsprechende Hypothese wurde aufgestellt nachdem man festgestellt hat, dass die 20- bis 29jährigen geduldiger sind. Das ist die Definition von HARKing (Hypothesizing After Results are Known). Siehe Sedlmeier S.636.
- 💡 C ist richtig: "...noch weitere 50 Teilnehmer:innen zu rekrutieren". Siehe Sedlmeier S.639 ganz unten.
- 💡 D ist falsch: Ein Fälschen der Daten lässt sich aus dem Text nicht erkennen.
- 💡 E ist richtig: Personen mit chronischen Erkrankungen werden ausgeschlossen, weil sie den vermuteten Effekt abschwächen.